Teaching AI to Machine Parts
Bachelor thesis at TUM. PPO and SAC trained against a live hyperMILL CAM environment to pick tools and cutting parameters.
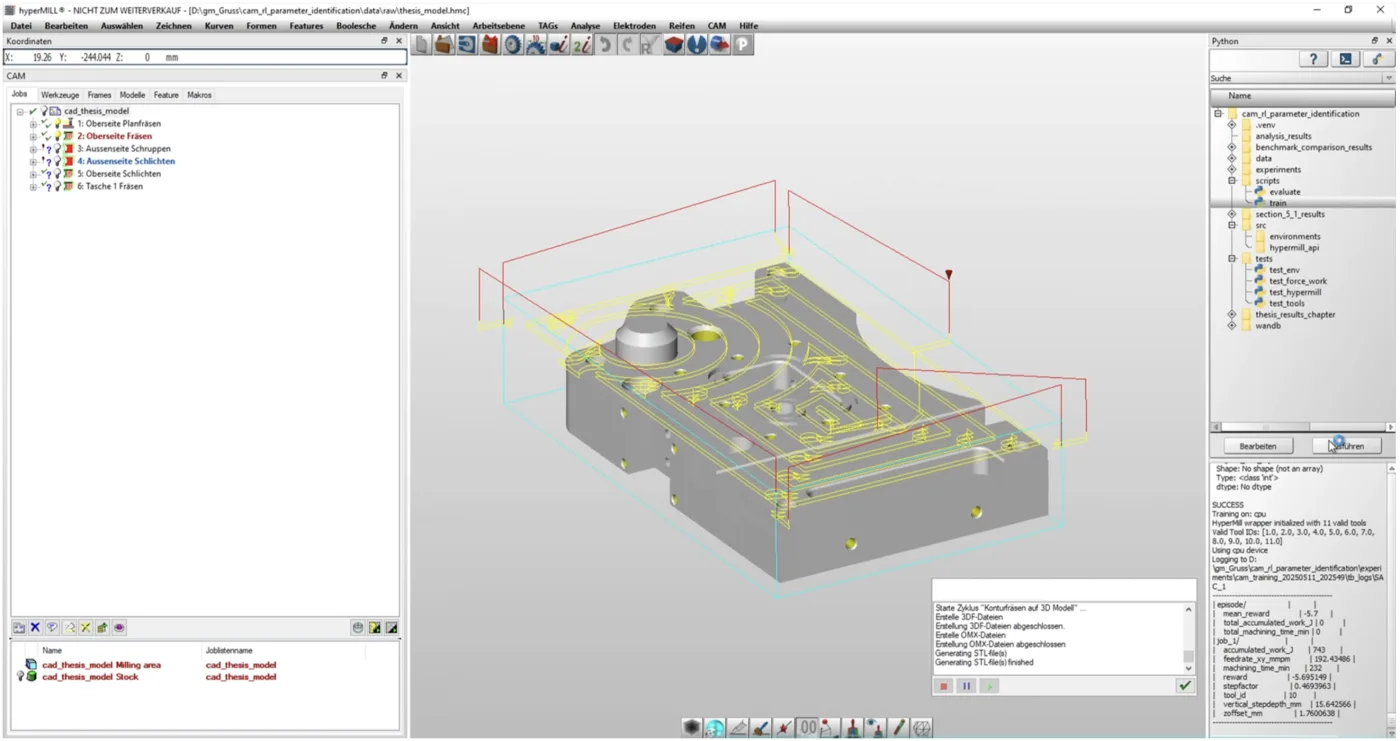
The hyperMILL CAM environment the agent acts on. Each step the agent picks a tool and four cutting parameters; hyperMILL recalculates the toolpath, simulates the cut, and returns the reward.
If you handed me the controls of a CNC milling machine and asked me to manufacture a precision part, I'd have no idea where to start. There are dozens of parameters to set: how fast should the cutting tool spin? How quickly should it move through the material? How deep should each cut be? Get these wrong, and at best you'll produce a useless chunk of metal. At worst, you'll snap a tool worth hundreds of dollars or damage a machine worth hundreds of thousands.
Yet experienced machinists make these decisions intuitively. After decades at the controls, they know that aluminum likes high speeds and deep cuts, while titanium demands patience and finesse. They can hear when a tool is struggling, feel when parameters need adjustment. This knowledge, accumulated over entire careers, typically retires with them.
For my bachelor thesis at TUM, I built a reinforcement learning system that learns machining parameters through trial and error — not by studying manuals or copying examples, but by actually trying parameter combinations against a live CAM simulator and learning from the results.
What I built
The state space is the catalog of available tools plus the current job (roughing or finishing, max cutting depth, last tool used). The action space is four continuous parameters: tool selection, feedrate, horizontal stepfactor, and vertical step depth. The reward combines normalized machining time against accumulated cutting work, which I derived from the Altintas force model — tangential, feed, and radial forces integrated over the toolpath length that hyperMILL hands back after each simulation.
The hard part wasn't the RL. It was making hyperMILL behave like an environment. The software is built for human operators clicking through menus, not for an automated system making thousands of experimental decisions per training run. Every parameter change required hyperMILL to recalculate the toolpath, simulate the cut, and produce the machine code. Each step took about 12 seconds of wall time. A 20-hour training run was 6,000 environment steps.
I trained two algorithms against this environment: PPO (Proximal Policy Optimization) and SAC (Soft Actor-Critic), both via Stable-Baselines3. They behaved very differently.
What the algorithms learned
SAC converged 24% faster than PPO and reliably completed all six machining operations under the optimization criteria. It also went through a clean phase transition: for the first thousand-odd episodes it tried random combinations, then around episode 1500 the performance metrics shot up and stayed there. It had found a strategy and committed.
PPO never settled. It kept exploring throughout training, second-guessing itself, and developed two strange biases: a preference for extreme values (parameters pinned to either the minimum or maximum of the allowed range, rarely anything in between) and an obsession with one particular 8mm endmill that it tried to use for almost everything. SAC was more balanced — different tools for different operations, parameter values in the middle of the allowed ranges.
The most informative result was comparing what each agent learned against industry-standard parameters from machining handbooks. For finishing operations — where surface quality is the whole point — the handbook recommends stepovers around 10% of tool diameter. SAC, optimizing only for time and force, picked stepovers of 60–100%. It found the fastest legal way to complete the job and ignored that the surface would look terrible. A textbook example of optimizing exactly what you told it to optimize, nothing more.
What it didn't capture
The biggest structural limit was generalization. The agent could only learn one part at a time. Train it on a different part, and it had to start from scratch with another 20-hour training run. A human machinist who has learned to machine one aluminum bracket immediately applies that knowledge to a similar one. The system had no such ability.
There was also no notion of context. The reward function knew about time and force; it didn't know that some materials are expensive, that some features are cosmetic and others critical, or that machine time may be cheaper than tool life on a given job. Working on this gave me a real respect for what experienced machinists actually do — what looks like parameter selection turns out to involve dozens of judgments learned through expensive mistakes, and the reward function I had access to could only see two of them.
What would actually need to change
A version of this worth running on a real machine would need three things the thesis didn't have. A reward that includes surface quality and tool wear, not just time and force — otherwise the agent will keep finding the fastest way to ruin a finish. A policy that conditions on part geometry directly, so it can transfer between parts instead of retraining for twenty hours each time. And a calibration loop against real machining data, because the Altintas force model is only as good as its coefficients and those drift across materials and tool conditions.
The thesis showed the integration is feasible and identified which of these are the load-bearing problems. None of them is unsolved in the literature; the work is in stitching them onto a CAM environment that wasn't built for it. That's the part that actually makes a difference on the shop floor.