A Worn Skill-Capture System
A solo, four-month reimplementation of a worn skill-capture glove — hardware, SLAM, and policy, end-to-end.

V3 glove. Custom DAQ board on the back of the wrist; four MLX90393 Hall sensors at the joints. (The on-glove cameras are from an earlier stereo build; production pose tracking uses an externally-mounted GoPro.)
This is a glove that records what your hands do, so a robot can learn from it later. The hardware is a custom DAQ board on the back of the wrist, four Hall sensors at the finger joints, two time-of-flight sensors, and a GoPro mounted to the back of the hand for camera pose. The project's experimental contribution is a force-correlated Hall Bz signal on compliant glove joints, measured below. The form factor mirrors Sunday Robotics' published Skill Capture Glove; their internals aren't public, so everything inside is independent. Code, schema, and a single-CLI reproduction are in the public repo; the paper PDF covers the full system.
Four months ago I'd never designed a circuit board. The board on the wrist captured all 182 demonstrations.
Why this project
Imitation learning for dexterous manipulation is bottlenecked by demonstration data. Robot teleoperation produces high-quality demos at low throughput; UMI raised the throughput by putting the capture rig on the human hand instead — a handheld stereo gripper with monocular SLAM that captures training data anywhere. What handheld grippers don't give you is per-joint proprioception — particularly squeeze force, which is what distinguishes the hand reached the cup from the hand grasped the cup. Sunday's published glove adds finger-joint sensing to the same paradigm; the internals aren't open.
This is an open reimplementation of the form factor with the per-joint sensing UMI doesn't have. Four Hall sensors give per-joint angle through Bx and By; the third axis, Bz, turns out to track squeeze force on the joints whose linkage is deliberately compliant — measured below.
What I built
The capture pipeline is five stages: capture, offload+ingest, SLAM, alignment, training. A person wears the glove, presses record on the GoPro, performs the task, and stops. Two recorders run independently — the GoPro writes 60 fps video to its own SD card; a Python recorder on the laptop streams 30 Hz of joint-sensor and ToF data over USB into a per-day master tape. Both clocks share UTC, set once per session by pointing the camera at GoPro Labs' precision-time QR page. Ingest slices the master tape per demo, SLAM produces a per-frame 6-DoF camera pose in a gravity-aligned tag world frame, and alignment interpolates the proprioceptive streams onto the video timeline. The output is one Parquet file per demonstration, with an identical schema across every demo.

The DAQ board sits on the back of the wrist and runs an STM32G431. Bit-bang I²C against a TCA9548A multiplexer drives four MLX90393 Hall sensors on thin FR4 PCBs at the index PIP, index MCP, three-finger PIP, and three-finger MCP joints; two VL53L1X time-of-flight sensors; and a QMI8658C IMU. The IMU shipped wrong: JLCPCB silently substituted a Tokmas-branded QMI8658C for the TDK ICM-42688-P I'd ordered — pin-compatible, completely different register map. Recovered via SPI WHO_AM_I scan and package-marking cross-reference.
Output is a single USB CDC stream at two packet rates: proprioception at 30 Hz (interpolated to the GoPro's 60 fps frame timeline at align time) and IMU at ~680 Hz observed against a 998 Hz nominal. The residual USB CDC backpressure isn't root-caused, but the policy doesn't consume the DAQ IMU; SLAM reads the GoPro's GPMF IMU instead.

The fingers are 3D-printed PLA. Each PIP joint carries a deliberate axial slit that gives the joint a known, tuned compliance under fingertip load. The compliance lets the magnet translate axially toward the Hall sensor under load — the geometric basis for the Bz force-correlation result below.
The policy is ACT — Action-Chunked Transformer, the architecture from ALOHA. I picked ACT over diffusion policy for two reasons. First, the mug-on-coaster task routinely has the coaster out of frame mid-pickup, and ACT's 5-second action horizon (300 frames at 60 fps) lets the policy plan past those gaps even though its observation horizon is only two frames. Second, on 182 demonstrations and a single task, chunked-action prediction with a CVAE was a more natural fit at this dataset size and compute budget than per-step diffusion. Observation is 23-D (relative end-effector position 3 + 6D rotation 6 + raw Hall 12 + ToF 2); action is 21-D (same minus ToF). The encoder is a CVAE; the decoder is a 7-layer DETR-style transformer over a frozen DINOv2 ViT-S/14 backbone. 38.7M parameters total, 16.6M trainable. I trained on a single L40S on the BU Shared Computing Cluster.
Eight SLAM backends
The SLAM stage changed eight times in four months. The pivots aren't variations on one problem — the failure modes shifted in kind, and that's the point of the chain.
I started with DROID-SLAM because dense visual-only SLAM was the most likely to "just work" on monocular video. It crashed on Colab — lietorch CUDA timeout, GPU SIFT failures — and the cloud-only debug surface didn't survive a real session.
I switched to COLMAP SfM offline against 17 demo sessions. Cross-session position RMSE was 18 cm, scale variation was 25.4% across sessions, and 0.5% of frames came back at physically impossible velocities. SfM without inertial fusion can't pin a consistent metric across sessions.
That sent me to custom stereo SIFT triangulation — stereo gives metric anchoring at acquisition time. Ruler test came back 1.2 m → 1.6 m (33% scale error). Triangulation alone isn't enough; you need full visual-inertial fusion in one optimizer.
Next was OKVIS2-X, a production-grade stereo VIO. Calibrated with Kalibr at 0.81 px reprojection. Worked with the fingers off the boards. Once I assembled the gloves with the fingers on, OKVIS2 started failing — finger occlusion ate the stereo overlap. The 81° HFOV cameras had only 36° clean overlap with the fingers off, and overlap collapsed to −13° when fingers approached the centerline. CIL237 fisheye lenses (122° HFOV, 77° overlap) didn't fix it. The cameras were on the wrong rigid body.
Three sentences hide a lot of grinding. Each Kalibr session is a waving routine in front of an AprilGrid. My house had AprilGrid sheets taped to monitors, walls, and bookshelves for two months. The first ten calibrations were getting Kalibr to converge; the next ten were chasing reprojection numbers I didn't trust. By the end of the OKVIS2 era I knew the config file by heart and didn't believe any of it.
I tried custom GTSAM v1, v2, v3 — three iterations of in-house factor graphs with CoTracker keypoints and IMU pre-integration. v2 converged on one hand-picked session at 0.5% scale error. On novel sessions, scale collapsed by 21× because landmarks were frozen at first observation and reused across sessions without re-optimization. The fix would have been a full bundle-adjustment pass over the whole map. I never built it.
Six weeks of OV9782 work, three custom factor graphs, one Hero 5 detour, and a running pile of calibrations I'd thrown out — and I finally accepted the cameras weren't the problem to fix. I pivoted to GoPro Hero 10 + UMI's published pipeline (ORB-SLAM3 + UMI's Kalibr Docker image, no recalibration). First mapping run: 99.6% tracking on an 83-second clip. First demo localized against that map: 99.5%, with the demo-start pose landing 1.2 cm from the mapping trajectory's endpoint.
The camera was the bottleneck, not the algorithm. The OV9782 code went into _archive/.
ORB-SLAM3 hit a different ceiling. The community reproduction rate for UMI's ORB-SLAM3 stage hovers around 20%, the chicheng/orb_slam3 Docker image is closed-source, and every 2024–2026 UMI successor paper (FastUMI, UMI-3D, ActiveUMI) replaces the SLAM stage. So I did the same.
The current production stack is HLoc — Hierarchical-Localization: SuperPoint keypoints, LightGlue matching, NetVLAD retrieval, COLMAP for the map model — plus a pose-graph batch smoother and a final Gaussian σ=5 filter. Same two-stage architecture as ORB-SLAM3 (build a map once, localize each demo against it), but learned features with retrieval are materially more robust on hard scenes. On three demos that ORB-SLAM3 had failed or railed on, HLoc localized 100% of frames.
The pattern across the eight backends is failure modes shifting in kind: cloud-only debug surface, no metric anchor, no full bundle adjustment, the wrong rigid body, a closed-source reproduction ceiling. At each fork the right move was to change the system, not tune a stack already at its diagnosed limit. What carried forward across pivots wasn't the algorithm — it was the evaluation infrastructure. Every backend wrote the same camera_trajectory.csv schema, every session went through the same per-demo quality verdict, and every demo emitted the same episode.parquet. The optimizer underneath changed eight times; the training-side schema has been stable since 2026-04-18, across two SLAM swaps after that date.
What works
Three pieces of evidence. None of them is "policy succeeds at task on a real robot" — deploying on an actuated arm is out of scope. What's here is the offline capture-and-training half.
SLAM versus a Kalibr AprilGrid. I built a controlled validation harness using a 6×6 AprilGrid (tag36h11, 25.8 mm tags) as the truth source. Six clips: one for the SfM map, five for validation, covering static no-cup, static cup-in-hand, and slow board-circle scenarios.
- Static no-cup. HLoc 8.3 mm p95 versus AprilGrid PnP 8.1 mm p95. The residual is within 0.2 mm of the AprilGrid PnP physical noise floor on the same frames — further gains on this regime have to come from capture-side hardware, not the SLAM stack.
- Static cup-in-hand. HLoc 29.2 mm p95 versus AprilGrid PnP 31.7 mm p95. HLoc is slightly better than the gold-standard board-PnP on this regime, because the σ=5 Gaussian helps and both are bounded by the same cup-occlusion physics.
Force-correlated Bz on compliant PIP joints. The PIP slit lets fingertip load translate the magnet axially toward the sensor; the magnetometer's Bz channel reads the resulting gap change. I ran a controlled scale-press: 20 ramped + 20 random-angle presses per assembly, 300–1300 g range, on the compliant 3F PIP joint and the rigid Index MCP joint as a negative control. Bz residual is computed against the angle-dependent baseline Bz_rest(θ) recovered from a separate rotation sweep.
- 3F PIP (compliant linkage): per-press linear fit of +1.29 counts/g, R² = 0.64.
- Index MCP (rigid linkage): flat residual under load. The rigid linkage doesn't translate the magnet axially, which is the expected failure of the design intent.
The claim is narrowed to compliant-linkage PIP joints. Extending it to MCP needs the V4 air-gap revision; that isn't done.

ACT policy on 182 demonstrations. 155 train + 27 held-out validation, four visually distinct workspaces. The production checkpoint reaches 28.8 mm position L1, 6.31° rotation L1, and 736 LSB Hall L1 on the validation set, scored against the HLoc + σ=5 ground truth. Best checkpoint at epoch 38 (150-epoch budget). The position error is roughly 3.5× the truth-source's own AprilGrid measurement floor — the model is the dominant residual, not label noise.
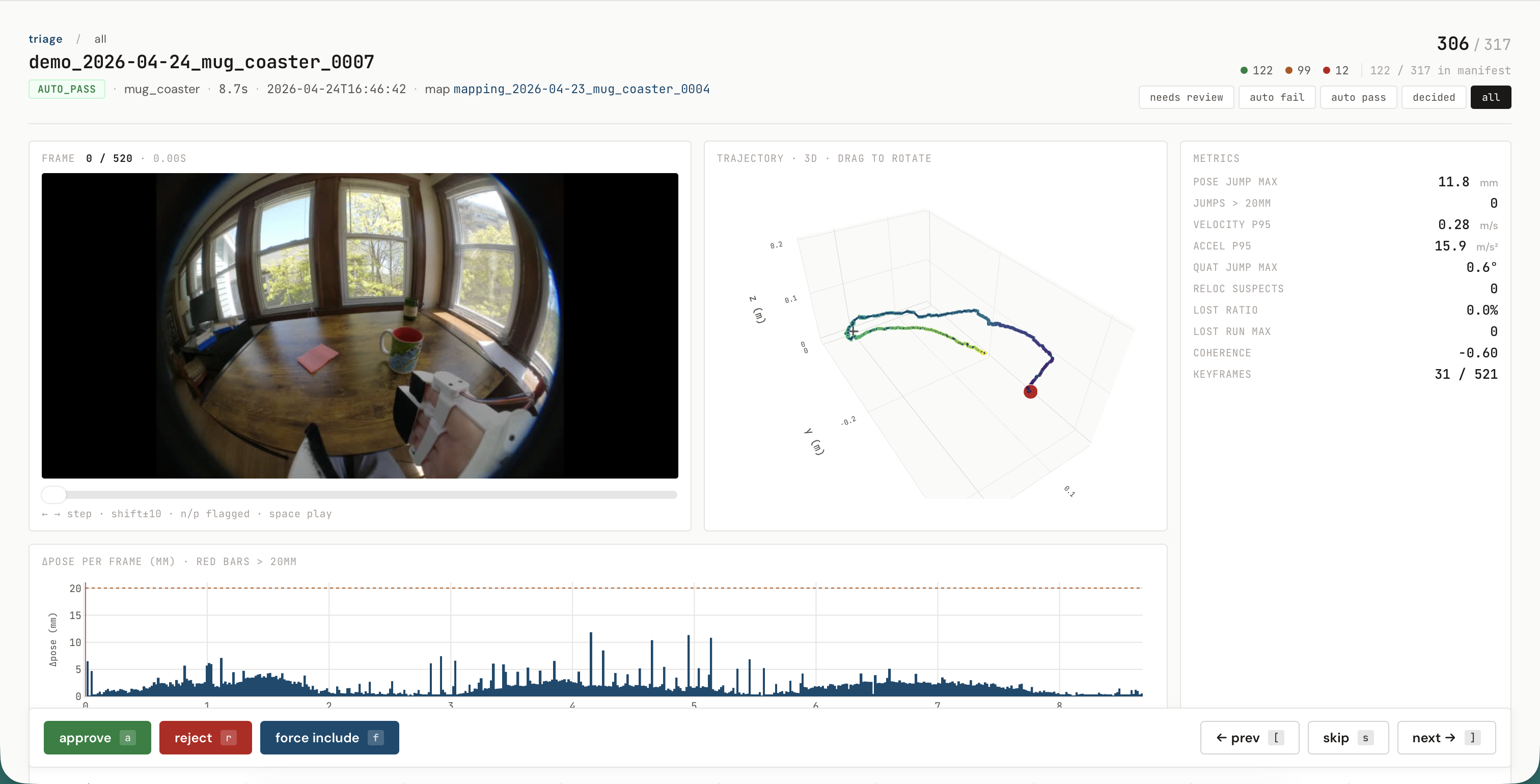
The 182 number is what survived a label-quality audit, plus a top-up the day after. The audit's trajectory-smoothness gate excluded 40 of the original 172 sessions (23%) for unphysical single-frame jumps; the worst two demos contained 340 mm single-frame teleports — a 20 m/s motion at 60 fps, on what was supposed to be continuous human hand motion. The artifacts were silent SLAM pose-graph re-anchoring events; the SLAM tracker reported is_lost = False on the offending frames, so tracking percentage didn't catch them. A scrubbable review dashboard, shipped alongside the pipeline, surfaced them frame by frame. I recorded 50 additional clean demonstrations the next day; the final training set is 182.
What's missing
The limits, in order of how much they bite.
- No actuated arm. This is offline imitation learning trained on human demonstrations. The metric is L1 against trajectory ground truth, not task-completion rate on a robot. Deployment would convert the offline metric into a behavior and might expose modeling gaps.
- Force sensing is PIP-only. The compliant-linkage joints work; rigid-linkage MCP joints need a V4 air-gap revision before they can carry force.
- Single task, single operator, single map per scene. All 182 demonstrations were recorded by one operator on one task across four workspaces; cross-task and cross-wearer generalization weren't measured. HLoc localizes against a per-environment SfM map, so a new scene needs a fresh mapping clip and a rebuilt atlas.
- AprilGrid bound is on static and slow-motion frames. Fast pickup-and-place motion isn't separately bounded against ground truth.
- CVAE collapse may be a symptom, not the bottleneck. Five recipe ablations on top of the production baseline returned to the same val L1 plateau; the latent is responding to a flat utility landscape, so the next bottleneck is upstream of the CVAE.
- Fingertip geometry isn't optimized for fine manipulation. Some mug-on-coaster variants were clean, some were stubborn — usually because of how the rounded fingertip pads contacted small or thin parts. Pad geometry (sharper edges, softer compliance, interchangeable inserts) is the next mechanical experiment.
Built with
- UMI (Cheng Chi et al., RSS 2024) — Hero 10 + Docker stack the production pose pipeline forked from
- Hierarchical-Localization, SuperPoint, LightGlue, NetVLAD, COLMAP — production SLAM stack
- ACT (Tony Zhao et al., RSS 2023) — policy architecture
- DINOv2 — frozen ViT-S/14 visual backbone
- GoPro Labs precision-time QR — millisecond camera-to-laptop sync
Final project for ME740 (Vision, Robotics, and Planning, Boston University, Spring 2026), under Prof. John Baillieul. The full pipeline — hardware design files, firmware, capture, SLAM, alignment, and policy training — is MIT-licensed and reproduces end-to-end from a single CLI per stage.